php使用file_get_contents与curl直接采集网页时数据获取不完整,本文给予解决办法
问题
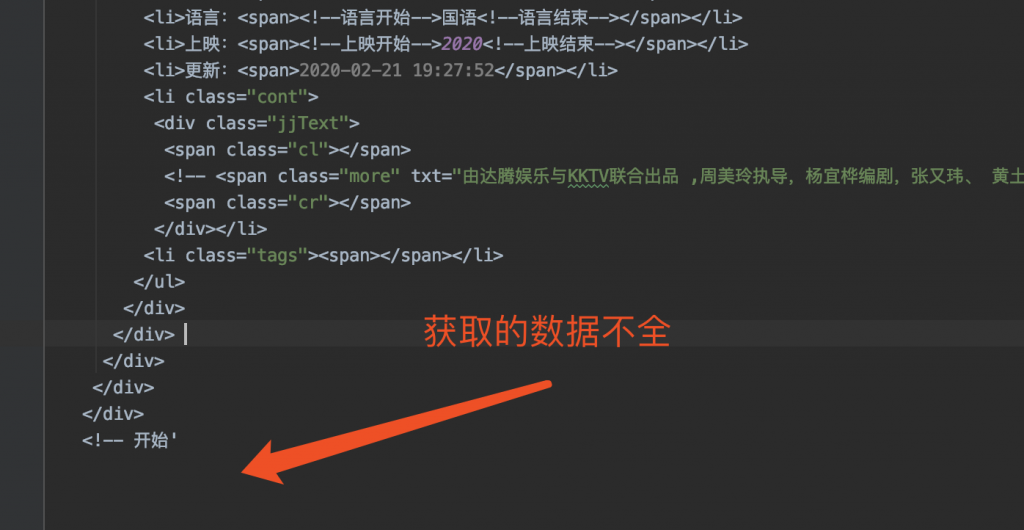
file_get_contents与curl直接采集网页时数据获取不完整
直接使用file_get_contents获取网页数据在大量获取时会出现不完整情况,后改进为:
function eyz_file_get_contents($collecturl,$timeout = 10){
//设置超时参数
$opts=array(
"http"=>array(
"method"=>"get",
"timeout"=>$timeout,
'header'=> "accept-encoding: gzip, deflate, sdch\r\n"//在请求的时候告诉服务器支持解gzip压缩的内容
),
);
////创建数据流上下文
$context = stream_context_create($opts);
return @file_get_contents("compress.zlib://".$collecturl,0,$context);
}通过上代码有所改善,但依旧存在不全的情况
解决方式
使用以下代码即可解决
function req_c)
{
$res = '';
$options = array_merge(array(
'follow_local' => true,
'timeout' => 30,
'max_redirects' => 4,
'binary_transfer' => false,
'include_header' => false,
'no_body' => false,
'cookie_location' => dirname(__file__) . '/cookie',
'useragent' => 'mozilla/4.0 (compatible; msie 6.0; windows nt 5.1',
'post' => array() ,
'referer' => null,
'ssl_verifypeer' => 0,
'ssl_verifyhost' => 0,
'headers' => array(
'expect:'
) ,
'auth_name' => '',
'auth_pass' => '',
'session' => false
) , $options);
$options['url'] = $url;
$s = curl_init();
if (!$s) return false;
curl_setopt($s, curlopt_url, $options['url']);
curl_setopt($s, curlopt_httpheader, $options['headers']);
curl_setopt($s, curlopt_ssl_verifypeer, $options['ssl_verifypeer']);
curl_setopt($s, curlopt_ssl_verifyhost, $options['ssl_verifyhost']);
curl_setopt($s, curlopt_timeout, $options['timeout']);
curl_setopt($s, curlopt_maxredirs, $options['max_redirects']);
curl_setopt($s, curlopt_returntransfer, true);
curl_setopt($s, curlopt_followlocation, $options['follow_local']);
curl_setopt($s, curlopt_cookiejar, $options['cookie_location']);
curl_setopt($s, curlopt_cookiefile, $options['cookie_location']);
if (!empty($options['auth_name']) && is_string($options['auth_name']))
{
curl_setopt($s, curlopt_userpwd, $options['auth_name'] . ':' . $options['auth_pass']);
}
if (!empty($options['post']))
{
curl_setopt($s, curlopt_post, true);
curl_setopt($s, curlopt_postfields, $options['post']);
//curl_setopt($s, curlopt_postfields, array('username' => 'aeon', 'password' => '111111'));
}
if ($options['include_header'])
{
curl_setopt($s, curlopt_header, true);
}
if ($options['no_body'])
{
curl_setopt($s, curlopt_nobody, true);
}
if ($options['session'])
{
curl_setopt($s, curlopt_cookiesession, true);
curl_setopt($s, curlopt_cookie, $options['session']);
}
curl_setopt($s, curlopt_useragent, $options['useragent']);
curl_setopt($s, curlopt_referer, $options['referer']);
$res = curl_exec($s);
$status = curl_getinfo($s, curlinfo_http_code);
curl_close($s);
return $res;
}以上是一个更完整的curl的封装,可以相对的比较好的获取页面信息,curl的获取当数据量过大时,会分批进行数据获取,本地进行数据重组
至此,问题解决

目前评论:0